By Todd Loeppke
I have been around storage architecture since Milli Vanilli was caught lip-synching their songs. I have personally seen and experienced how the role of a storage architect has changed over time. In recent years, as public clouds became a critical tool in the IT architect tool bag, I have witnessed a significant shift in the skills required to maintain this title.
In the past, a storage architect needed to understand SCSI bus addressing, cable length limitations, disk rotation speeds and seek times, moving data around with Unix commands like cpio, dd and all the command line options for vg-, pv- and lv-create. As time progressed, skills included understanding disk array overhead, BIN files, async and sync replication, channel arbitrated loop vs. point to point, soft zoning vs. hard zoning, SLC and MLC flash and wear leveling…you get the idea.
With the prevalence of public clouds coupled with infrastructure as code driven by CI/CD (Continuous Integration / Continuous Deployment or Delivery), the need to understand the finer points of hardware have diminished. For storage architects, does that mean their skills are no longer needed? I don’t believe so, but the role has changed and the skills required to contribute to successful solutions are different. Today, there at least six general categories that storage architects should focus on. They are:
- Understanding the technical details of public cloud storage offerings
- Understanding the cost nuances of those offerings
- Understanding how to automate the creation and manipulation of the storage offerings (which requires more than shell scripting)
- Understanding how best to move data between different IaaS options
- The ability to utilise opens source software to solve storage related challenges
- Understanding how technologies like containers and serverless computing impact storage architectures
Understanding the technical storage details of public cloud storage offerings is not new, but it is different. Storage Architects are used to following storage vendor’s roadmaps and up-and-coming storage vendors. Today, they need focus on understanding the different storage options offered by leading public cloud vendors: AWS, Microsoft’s Azure and Google Cloud Platform (GCP). (If you can only focus on one, you should start with AWS since it offers the most robust options and features in my opinion…it’s a bit like learning Unix in the 90s — if you knew one vendor’s version well, you could easily learn another vendor’s versions). Instead of going to vendor EBCs (Executive Briefing Centres) or meeting for roadmap presentations under NDA, which are not generally available from the public cloud vendors, you have to keep up-to-date by following blogs, following knowledgeable people on Twitter and attending conferences put on by the major public cloud vendors. For example, there were seven storage-specific announcements and several other announcements with positive impacts to AWS storage services at the AWS re:Invent conference last November.
On AWS, you first need to first understand what storage tools are available in your tool bag. The three fundamental types of storage (block, file and object) are all available on the AWS platform.
For block storage, you have two types: non-persistent, and persistent.
- Non-persistent block devices are called EC2 Instance Stores which are only available on certain EC2 instance types and have predetermined sizes based on the instance type. Data on Instance Stores persist during the lifetime of the instance (including reboots) but data is lost if the instance is stopped or terminated or if there is a disk drive failure.
- Persistent block devices are called Elastic Block Stores (EBS). There are 4 EBS options listed below (a 5th – EBS option called “Magnetic” is now labeled “Previous Generation” which is where AWS services go to die):
- General Purpose SSD (gp2 – default)
- Provisioned IOPS SSD (io1)
- Throughput Optimised HDD (st1)
- Cold HDD (sc1)
For file storage, you have 2 Elastic File System (EFS) options:
- General Purpose (default)
- Max I/O
For object storage, you have 4 options:
- S3 Standard
- S3 Infrequently Access (IA)
- S3 Reduced Redundancy (RRS)
- Glacier (archive tier)
This storage menu is more complete than most in-house enterprise companies can provide to their customers. In the sections that follow, I will highlight a few examples where understanding the details of the storage service are necessary for a successful deployment.
Block Storage
As mentioned above, EC2 Instance Stores provide temporary block-level storage to an instance. This storage is physically attached to the host computer and is not redundant. This type of storage is usually used for buffer cache and other temporary data. Like most AWS storage options, there are some caveats with EC2 Instance Stores. Some instance types use Hard Drives (HDs) and some use Solid State Disks (SSDs). Some of the instances that use SSDs also support TRIM, which is a serial ATA interface that allows an operating system to tell an SSD which data can be wiped. If you need the maximum performance from your EC2 Instance Store you will need to initialize (pre-warm) your device UNLESS your instance supports EC2 Instance Stores on SDD and supports TRIM, then you do not need to pre-warm your block device.
EBS volumes are accessed over an IP network and are designed to have 5-9s of service availability. When you create a new volume, it automatically creates a second copy (replica) in the same Availably Zone (AZ) so there is no need for or benefit from using RAID for volumes that require 16TB or less of space. However, there are three situations in which you would need to use a RAID configuration:
- You need a volume greater than 16TB
- You have a throughput requirement greater than 500MB/s
- You have an IOPS requirement greater the 20,000 (based on a 16TB volume)
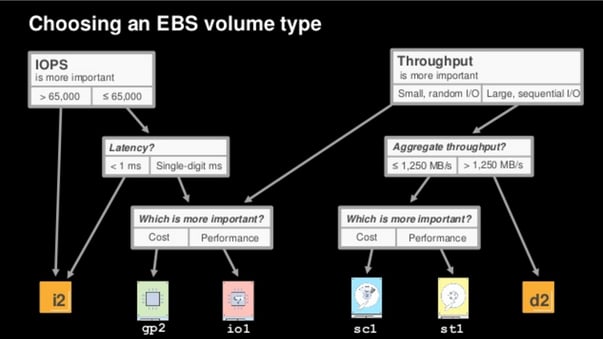
Regarding performance, there are two categories for EBS volumes. They are performance relative to IOPS (gp2 and io1), and throughput based on MB/s (st1 and sc1). gp2 and io1 IOs are based on a 16KB IO size while st1 and sc1 are based on a 1MB IO size. This is important to understand when we look at the use of burst credits and how they impact the performance of the different EBS volume types. Burst buckets credits for new gp2, st1 and sc1 volumes are full at the time of creation (the maximum bucket size is dependent volume sizes). gp2 credits are measured in IOPS while credits for st1 and sc1 are measured in MB/s. The rate of accumulation and how fast you can use the credits is different for each of the following three types:

For io1 volumes or Provisioned IOPS SSD, you are purchasing a consistent level of IOPS so bursting is not a factor. If the lowest I/O latency possible on an EC2 instance is required (< 1 ms), an Instance Store on an i2 instance is probably what you need. Volume size maximums are the same for all 4 types (16TB) but the minimum volume size is the smallest for gp2 (1GB), 4GB for io1 and 500GB for st1 and sc1.
There is no need to “pre-warm” new EBS volumes to experience the maximum performance. However, if a volume is created from an EBS snapshot and you need the maximum performance from the restored volume, you should pre-warm the volume since the blocks are lazy-loaded from S3 back to EBS. EBS Snapshots are a point in time copy stored on S3 of every modified block of the EBS volume. Subsequent snapshots only copy blocks that have changed. Snapshots can be copied across regions and accounts.
An EBS-optimised instance is an EC2 instance that dedicates network bandwidth to EBS traffic. In an instance without EBS-optimisation, EBS traffic shares network bandwidth with other EC2 network traffic (like: database, S3 and internet traffic). For some instances types, this feature is enabled by default (c4, d2, m4, p2, r4 and x1); on other instance types, you must enable this feature. For instance types that already have 10/12Gbps connectivity, that bandwidth is shared with EBS since that is currently the max total bandwidth available to an instance. With the I3 and C5 announcements made at Amazon’s 2016 re:Invent conference, this number will increase in 2017. To experience the maximum storage performance possible on an EC2 instance, pay attention so that there is not a mismatch in storage pipe (throughput) and what the volume(s) attached are capable of.
Regarding disk encryption, EBS volumes and snapshots provide an encryption option, but for Instance Stores you would need to provide your own solution for encrypting the data.
This slide (below) was presented by Rob Alexander, AWS Principle Solution Architect, during the Deep Dive on Amazon Elastic Block Store at the 2016 re:Invent conference and does a great job summarizing which EBS volume type to use.
File storage – Elastic File System (EFS)
EFS is a scalable file storage that EC2 instances can access via NFSv4.1. Pricing is based on the average storage space used in GB-Months and automatically grows and shrinks so it’s easy to use. It stores filesystem objects across multiple AZs so it is highly available, which makes it more robust than many commercial Network Attached Storage (NAS) offerings. With EFS you can create up to 125 filesystems per account. Currently, it is only available in 5 AWS regions.
To access an EFS, you create a mount target for each AZ in your VPC. In 2107, a feature will be added that allows a single DNS name automatically resolve to the endpoint in the local AZ. VPC security groups and network ACLs should be used to control traffic to the filesystem, and administrative access should be controlled Identity and Access Management (IAM) policies.
As mentioned above there are two EFS options: General Purpose (default), and Max I/O. General Purpose mode should be used in low latency use cases and Max I/O should be used for scale-out use cases. If you are not sure which to use, start with General Purpose mode. Use CloudWatch metrics like BurstCreditBalance and PercentIOLimit to help you determine if you are constrained by the General Purpose mode. Also, make sure you use the recommended Linux kernel version for the best performance possible. Maximum performance will take some testing where you will want to parallelise threads and instances while matching your use to the optimal instance type.
Often the biggest negative reactions to EFS is around the cost. At $.30/GB-month (US Regions), it is the highest GB-Month storage offering AWS has. There are a few things to keep in mind, though, regarding the cost. First, the cost is based on storage used,unlike EBS which is storage provisioned. So, like S3, you are only paying for the storage space you consume. Second, it automatically grows and shrinks so you don’t need to manage that aspect. Last, and most important, if you decide to build you own NAS using EBS volumes, by the time you make it highly available across multiple AZs with similar compute power and include the inter-AZ data transfer cost, you will probably spend much more per month.
Also announced at re:Invent was support for EFS over AWS Direct Connect, and encryption which will soon be added to at no extra cost. The Direct Connect option allows your on-prem servers to access EFS. This allows EFS to be used for system migrations, storage tiering and backup / DR. As with access to any NAS over a WAN, network latency will make some use cases impractical.
Object Storage
AWS’ S3 object storage is one of the early pillars of AWS and it is used behind the scenes to enable many other AWS services. S3 provides four different storage classes:
- S3 Standard
- S3 Infrequently Access (IA)
- S3 Reduced Redundancy (RRS)
- Glacier (archive tier)
The differences between all four classes are around durability, availability, and the frequency of access.
Standard, IA and Glacier all have the same durability rating (11-9s) while RRS is only 4-9s. Standard, RRS and Glacier have 4-9s of availability while IA is only 3-9s. You can save money using the different classes depending on how often you access data and how durable/reliable you need the data. If unsure, Standard is where you should start.
Once you better understand your data and how it is accessed, you can use lifecycle policies [Information Life Cycle (ILM) for objects] to migrate your data to a less expensive tier (IA or Glacier) or expire your data. RRS should only be used for noncritical data or data that can easily be reproduced since the durability level is much lower.
Encryption [Server Side Encryption (SSE) or Server Side Encryption with Customer-Provided Keys (SSE-C)] are available, or you can use your own encryption solution before storing the object to S3. AWS KMS can also be used to manage your encryption keys.
With S3 there is no limit on the number of objects you can store and an individual object can be as large as 5TB. The largest object that can be stored with a single PUT is 5GB. For storing large objects, the multipart upload capability should be used to improve upload performance.
Versioning and Cross-Region Replication (CCR) are useful properties that can be enabled on Storage Buckets, which is a logical grouping of objects (and different from burst buckets mentioned above). Versioning allows existing objects to be preserved and CCR makes it easy to replicate objects in a bucket to another AWS Region. Metadata and any associated ACLs are also replicated to the destination bucket and different lifecycle policies can be used on the source and destination buckets.
Four new S3 features were released at the last re:Invent conference:
- S3 Object Tagging
- S3 Analytics
- S3 Inventory
- 13 New S3 CloudWatch Metrics
Details on these announcements can be found here (link). It is impressive to see how AWS continues to enhance the capability of the S3 service while continuing to reduce the cost (the most recent cost reduction being announced on 11/21/16).
Last, for loading data into S3, AWS provides multiple options. This slide (below) was presented by Susan Chan, AWS Senior Product Manager, during the Deep Dive on Amazon S3 at the 2016 re:Invent conference:

As you can see from my overview of some of the technical capabilities of AWS’ three storage types (block, file, and object), there’s a lot to understand in order to exploit the platform to its fullest. If you want to maintain your Storage Architect title or want to be included in storage architecture discussions, you’ll need to spend some time learning about storage in public clouds. But if you study the technical details a little further, you can be the real deal when it comes to finding a legit Storage Architect – not a lip-syncing imposter.